Inference
So far we have set the foundation for how we can represent probabilistic models with multiple random variables. These models are especially useful because they let us perform a task called "inference" where we update our belief about one random variable in the model, conditioned on new information about another. Inference in general is hard! In fact, it has been proven that in the worst case, the inference task, can be NP-Hard where $n$ is the number of random variables [1].
First we are going to practice it with two random variables (in this section). Then, later in this unit we are going to talk about inference in the general case, with many random variables.
Earlier we looked at conditional probabilities for events. The first task in inference is to understand how to combine conditional probabilities and random variables. The equations for both the discrete and continuous case are intuitive extensions of our understanding of conditional probability:
The Discrete Conditional
The discrete case, where every random variable in your model is discrete, is a straightforward combination of what you know about conditional probability (which you learned in the context of events). Recall that every relational operator applied to a random variable defines an event. As such the rules for conditional probability directly apply: The conditional probability mass function (PMF) for the discrete case:
Def: Conditional definition with discrete random variables.
\begin{align*} \P(X=x|Y=y)=\frac{P(X=x,Y=y)}{P(Y=y)} \end{align*}Def: Bayes' Theorem with discrete random variables.
\begin{align*} \P(X=x|Y=y)=\frac{P(Y=y|X=x)P(X=x)}{P(Y=y)} \end{align*}In the presence of multiple random variables, it becomes increasingly useful to use shorthand! The above definition is identical to this notation where a lowercase symbol such as $x$ is short hand for the event $X=x$: \begin{align*} \P(x|y)=\frac{P(x,y)}{P(y)} \end{align*} The conditional definition works for any event and as such we can also write conditionals using cumulative density functions (CDFs) for the discrete case: \begin{align*} \P(X \leq a | Y=y) &= \frac{\P(X \leq a, Y=y)}{\p(Y=y)} \\ &= \frac{\sum_{x\leq a} \P(X=x,Y=y)}{\P(Y=y)} \end{align*} Here is a neat result: this last term can be rewritten, by a clever manipulation. We can make the sum extend over the whole fraction: \begin{align*} \P(X \leq a | Y=y) &= \frac{\sum_{x\leq a} \P(X=x,Y=y)}{\P(Y=y)} \\ &= \sum_{x\leq a} \frac{\P(X=x,Y=y)}{\P(Y=y)} \\ &= \sum_{x\leq a} \P(X=x|Y=y) \end{align*}
In fact it becomes straight forward to translate the rules of probability (such as Bayes' Theorem, law of total probability, etc) to the language of discrete random variables: we simply need to recall that every relational operator applied to a random variable defines an event.
Mixing Discrete and Continuous
What happens when we want to reason about continuous random variables using our rules of probability (such as Bayes' Theorem, law of total probability, chain rule, etc)? There is a simple practical answer: the rules still apply, but we have to replace probability terminology with probability density functions. As a concrete example let's look at Bayes' Theorem with one continuous random variable.
Def: Bayes' Theorem with mixed discrete and continuous.
Let $X$ be a continuous random variable and let $N$ be a discrete random variable. The conditional probabilities of $X$ given $N$ and $N$ given $X$ respectively are: \begin{align*} f(X=x|N=n) = \frac{\P(N=n|X=x)f(X=x)}{\p(N=n)} && \end{align*} \begin{align*} \p(N=n|X=x) = \frac{f(X=x|N=n)\p(N=n)}{f(X=x)} \end{align*}These equations might seem complicated since they mix probability densities and probabilities. Why should we believe that they are correct? First, observe that anytime the random variable on the left hand side of the conditional is continuous, we use a density, whenever it is discrete, we use a probability. This result can be derived by making the observation: $$ \P(X = x) = f(X=x) \cdot \epsilon_x $$
In the limit as $\epsilon_x \rightarrow 0$. In order to obtain a probability from a density function is to integrate under the function. If you wanted to approximate the probability that $X = x$ you could consider the area created by a rectangle which has height $f(X=x)$ and some very small width. As that width gets smaller, your answer becomes more accurate:
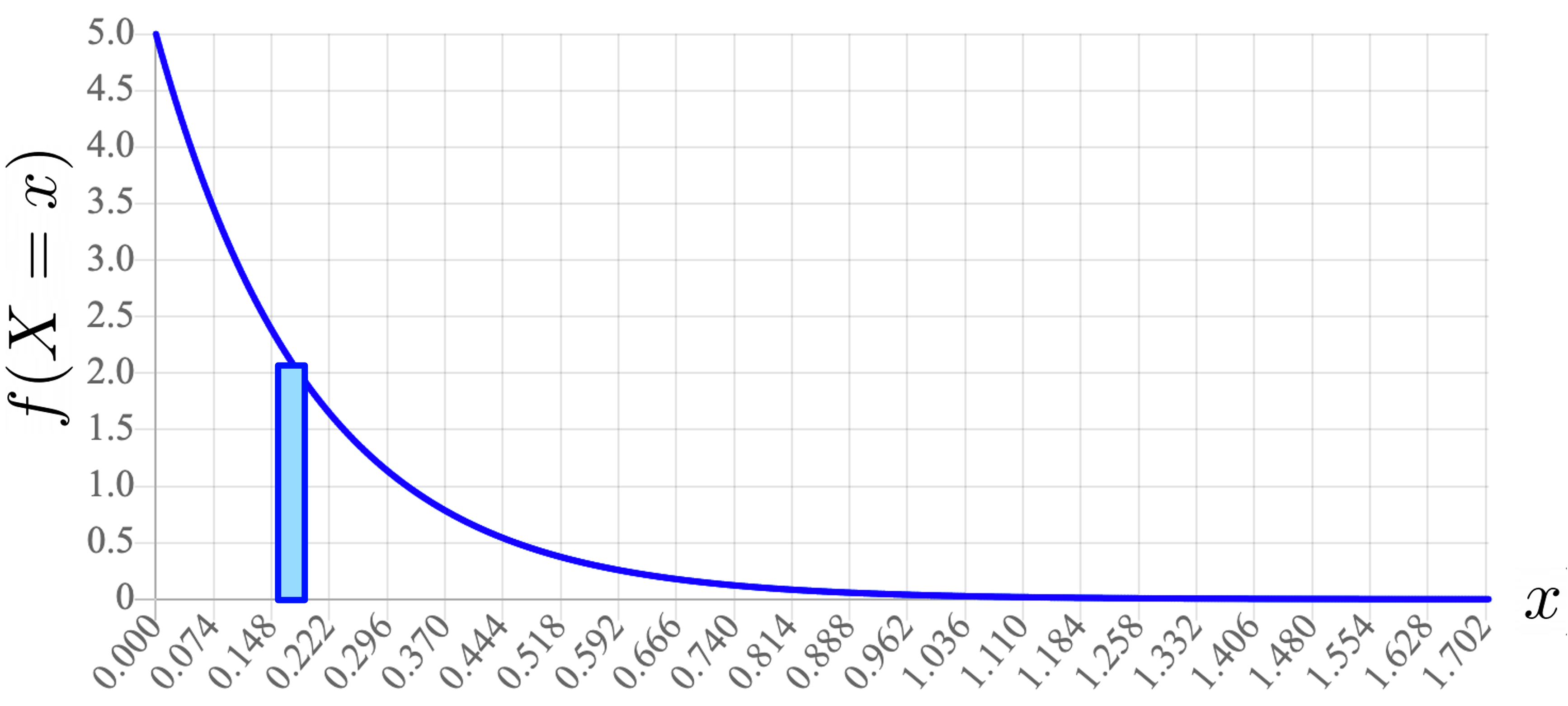
A value of $\epsilon_x$ is problematic if it is left in a formula. However, if we can get them to cancel, we can arrive at a working equation. This is the key insight used to derive the rules of probability in the context of one or more continuous random variables. Again, let $X$ be continuous random variable and let $N$ be a discrete random variable: \begin{align*} \p(N=n|X=x) &= \frac{P(X=x|N=n)\p(N=n)}{P(X=x)} &&\text{Bayes' Theorem}\\ &= \frac{f(X=x|N=n) \cdot \epsilon_x \cdot \p(N=n)}{f(X=x) \cdot \epsilon_x} &&\P(X = x) = f(X=x) \cdot \epsilon_x \\ &= \frac{f(X=x|N=n) \cdot \p(N=n)}{f(X=x)} &&\text{Cancel } \epsilon_x \\ \end{align*}
This strategy applies beyond Bayes' Theorem. For example here is a version of the Law of Total Probability when $X$ is continuous and $N$ is discrete: \begin{align*} f(X=x) &= \sum_{n \in N} f(X=x | N = n) \p(N = n) \end{align*}
Probability Rules with Continuous Random Variables
The strategy used in the above section can be used to derive the rules of probability in the presence of continuous random variables. The strategy also works when there are multiple continuous random variables. For example here is Bayes' Theorem with two continuous random variables.
Def: Bayes' Theorem with continuous random variables.
Let $X$ and $Y$ be continuous random variables. \begin{align*} f(X=x|Y=y) = \frac{f(X=x,Y=y)}{f(Y=y)} \end{align*}Example: Inference with a Continuous Variable
Consider the following question:

$X | G = 1$ is $N(μ = 160, σ^2 = 7^2)$
$X | G = 0$ is $N(μ = 165, σ^2 = 3^2)$ \begin{align*} \p(G = 1 | X = 163) &= \frac{f(X = 163 | G = 1) \P(G = 1)}{f(X = 163)} && \text{Bayes} \end{align*} If we can solve this equation we will have our answer. What is $f(X = 163 | G = 1)$? It is the probability density function of a gaussian $X$ which has $\mu=160, \sigma^2 = 7^2$ at the point $x$ is 163: \begin{align*} f(X = 163 | G = 1) &= \frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2}\Big(\frac{x-\mu}{\sigma}\Big)^2} && \text{PDF Gauss} \\ &= \frac{1}{7 \sqrt{2 \pi}} e^{-\frac{1}{2}\Big(\frac{163-160}{7}\Big)^2} && \text{PDF } X \text{ at } 163 \end{align*} Next we note that $\P(G = 0) = \P(G = 1) = \frac{1}{2}$. Putting this all together, and using the law of total probability to compute the denominator we get: \begin{align*} \p&(G = 1 | X = 163) \\ &= \frac{f(X = 163 | G = 1) \P(G = 1)}{f(X = 163)} \\ &= \frac{f(X = 163 | G = 1) \P(G = 1)}{f(X = 163 | G = 1) \P(G = 1) + f(X = 163 | G = 0) \P(G = 0)}\\ &= \frac{\frac{1}{7 \sqrt{2 \pi}} e^{-\frac{1}{2}\Big(\frac{163-160}{7}\Big)^2} \cdot \frac{1}{2}}{\frac{1}{7 \sqrt{2 \pi}} e^{-\frac{1}{2}\Big(\frac{163-160}{7}\Big)^2} \cdot \frac{1}{2} + \frac{1}{3 \sqrt{2 \pi}} e^{-\frac{1}{2}\Big(\frac{163-165}{3}\Big)^2} \cdot \frac{1}{2}} \\ &= \frac {\frac{1}{7} e^{-\frac{1}{2}\Big(\frac{9}{49}\Big)} } {\frac{1}{7} e^{-\frac{1}{2}\Big(\frac{9}{49}\Big)} + \frac{1}{3} e^{-\frac{1}{2}\Big(\frac{4}{9}\Big)^2} }\\ &\approx 0.328 \end{align*}